快速开始
RAGFlow 是一个基于深度文档理解的开源 RAG(检索增强生成)引擎。当与 LLM 集成时,它能够提供真实可靠的问题回答能力,并基于各种复杂格式数据的可靠引用。
本快速开始指南描述了从以下步骤的完整流程:
- 启动本地 RAGFlow 服务器
- 创建知识库
- 干预文件解析
- 基于您的知识库建立 AI 聊天
我们官方支持 x86 CPU 和 Nvidia GPU,本文档提供了在 x86 平台上使用 Docker 部署 RAGFlow 的说明。虽然我们也在 ARM64 平台上测试 RAGFlow,但我们不维护 ARM 的 RAGFlow Docker 镜像。
如果您在 ARM 平台上,请按照此指南构建 RAGFlow Docker 镜像。
前置要求
- CPU ≥ 4 核心 (x86);
- 内存 ≥ 16 GB;
- 磁盘 ≥ 50 GB;
- Docker ≥ 24.0.0 和 Docker Compose ≥ v2.26.1。
如果您尚未在本地机器(Windows、Mac 或 Linux)上安装 Docker,请参阅安装 Docker 引擎。
启动服务器
本节提供了在 Linux 上设置 RAGFlow 服务器的说明。如果您使用不同的操作系统,不用担心。大多数步骤都是相似的。
-
克隆仓库:
$ git clone https://github.com/infiniflow/ragflow.git
$ cd ragflow
$ git checkout -f v0.20.5
$ cd docker -
使用预构建的 Docker 镜像并启动服务器:
注意下面的命令下载
v0.20.5-slim版本的 RAGFlow Docker 镜像。请参考下表了解不同 RAGFlow 版本的描述。要下载不同于v0.20.5-slim的 RAGFlow 版本,请在使用docker compose启动服务器之前在 docker/.env 中相应地更新RAGFLOW_IMAGE变量。例如:对于完整版本v0.20.5,设置RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5。# 使用 CPU 进行嵌入和 DeepDoc 任务:
$ docker compose -f docker-compose.yml up -d
# 停止服务
docker compose -f docker-compose.yml down# 删除数据卷
$ docker volume ls
$ docker volume rm docker_esdata01
$ docker volume rm docker_minio_data
$ docker volume rm docker_mysql_data
$ docker volume rm docker_redis_data
<APITable>
| RAGFlow 镜像标签 | 镜像大小 (GB) | 包含嵌入模型和 Python 包? | 稳定性? |
|---|---|---|---|
v0.20.5 | ≈9 | ✔️ | 稳定版本 |
v0.20.5-slim | ≈2 | ❌ | 稳定版本 |
nightly | ≈9 | ✔️ | 不稳定 夜间构建 |
nightly-slim | ≈2 | ❌ | 不稳定 夜间构建 |
</APITable>
v0.20.5 和 nightly 版本中包含的嵌入模型有:
- BAAI/bge-large-zh-v1.5
- maidalun1020/bce-embedding-base_v1
这两个嵌入模型专门针对英语和中文进行了优化,因此如果您使用它们来嵌入其他语言的文档,性能将会受到影响。
显示的镜像大小指的是下载的 Docker 镜像的大小,它是压缩的。当 Docker 运行镜像时,它会解压缩,导致磁盘使用量显著增加。例如,精简版镜像解压后会扩展到约 7 GB。
-
服务器启动并运行后检查服务器状态:
$ docker logs -f ragflow-server以下输出确认系统成功启动:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
如果您跳过此确认步骤并直接登录 RAGFlow,您的浏览器可能会提示 network anomaly 错误,因为此时您的 RAGFlow 可能尚未完全初始化。
- 在您的网络浏览器中,输入服务器的 IP 地址并登录 RAGFlow。
使用默认设置时,您只需要输入 http://IP_OF_YOUR_MACHINE(不包含端口号),因为使用默认配置时可以省略默认 HTTP 服务端口 80。
配置 LLM
RAGFlow 是一个 RAG 引擎,需要与 LLM 配合工作以提供基于事实、无幻觉的问题回答能力。RAGFlow 支持大多数主流 LLM。有关支持的模型的完整列表,请参阅支持的模型。
要添加和配置 LLM:
-
点击页面右上角的您的徽标 > 模型提供商。
-
点击所需��的 LLM 并相应地更新 API 密钥。
-
点击系统模型设置来选择默认模型:
- 聊天模型
- 嵌入模型
- 图像到文本模型
- 等等
某些模型,如图像到文本模型 qwen-vl-max,是特定 LLM 的附属模型。您可能需要更新 API 密钥才能访问这些模型。
创建您的第一个知识库
您可以在 RAGFlow 中向知识库上传文件并将其解析为知识库。知识库实际上是知识库的集合。RAGFlow 中的问题回答可以基于特定的知识库或多个知识库。RAGFlow 支持的文件格式包括文档(PDF、DOC、DOCX、TXT、MD、MDX)、表格(CSV、XLSX、XLS)、图片(JPEG、JPG、PNG、TIF、GIF)和幻灯片(PPT、PPTX)。
要创建您的第一个知识库:
-
点击页面顶部中间的知识库标签 > 创建知识库。
-
输入您的知识库名称并点击确定确认您的更改。
您将被带到知识库的配置页面。
-
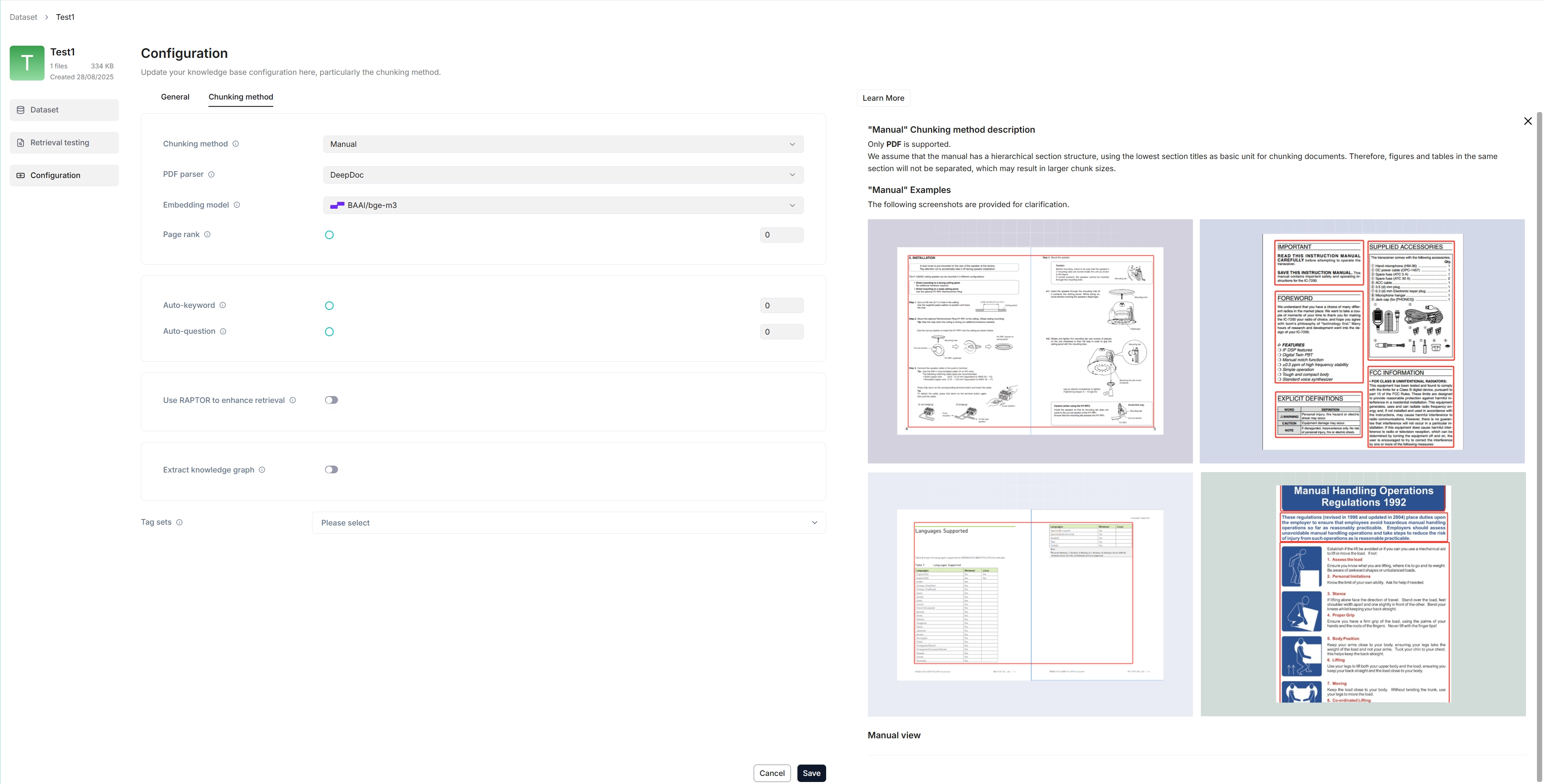
RAGFlow 提供多种分块模板,适用于不同的文档布局和文件格式。为您的知识库选择嵌入模型和分块方法(模板)。
一旦您选择了嵌入模型并使用它来解析文件,您就不能再更改它。显而易见的原因是,我们必须确保特定知识库中的所有文件都使用相同的嵌入模型进行解析(确保它们在相同的嵌入空间中进行比较)。
您将被带到知识库的知识库页面。
-
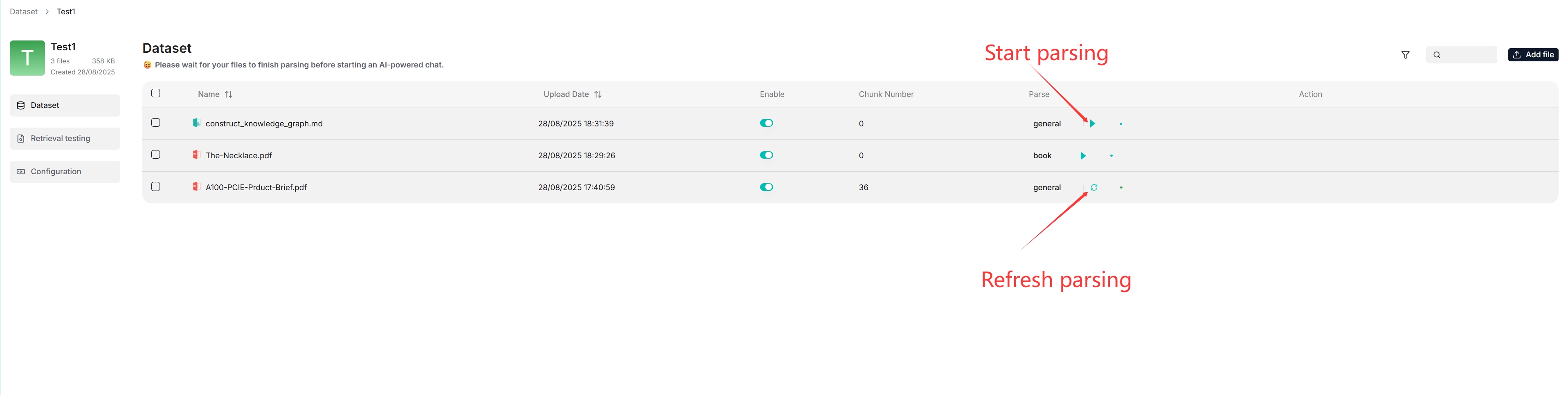
点击 + 新增文件 > 上传文件开始向知识库上传特定文件。
-
在上传的文件条目中,点击播放按钮开始文件解析:
干预文件解析
RAGFlow 具有可见性和可解释性,允许您查看分块结果并在必要时进行干预。要这样做:
-
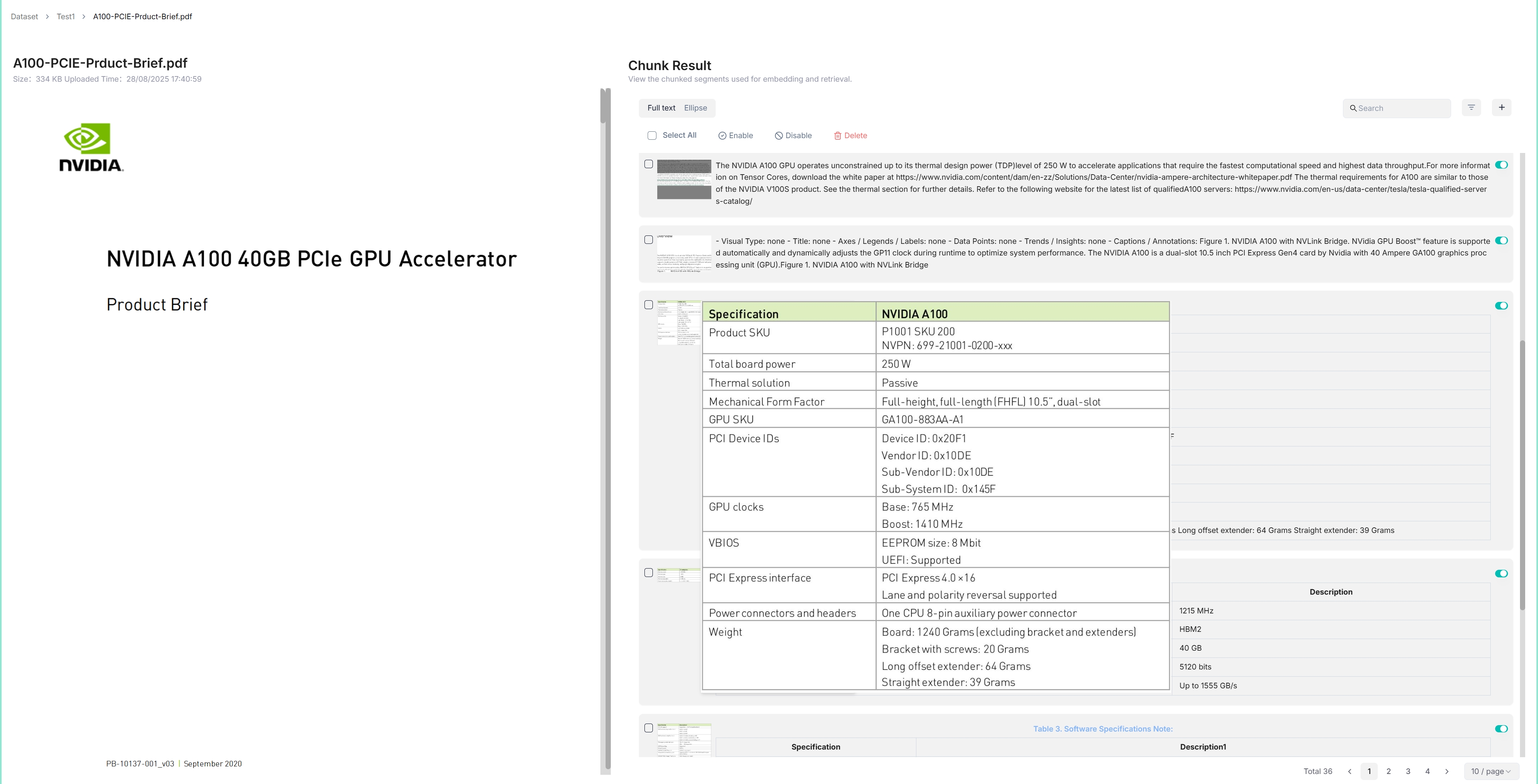
点击完成文件解析的文件以查看分块结果:
您将被带到分块页面:
-
双击分块文本以添加关键词或在必要时进行手动更改:
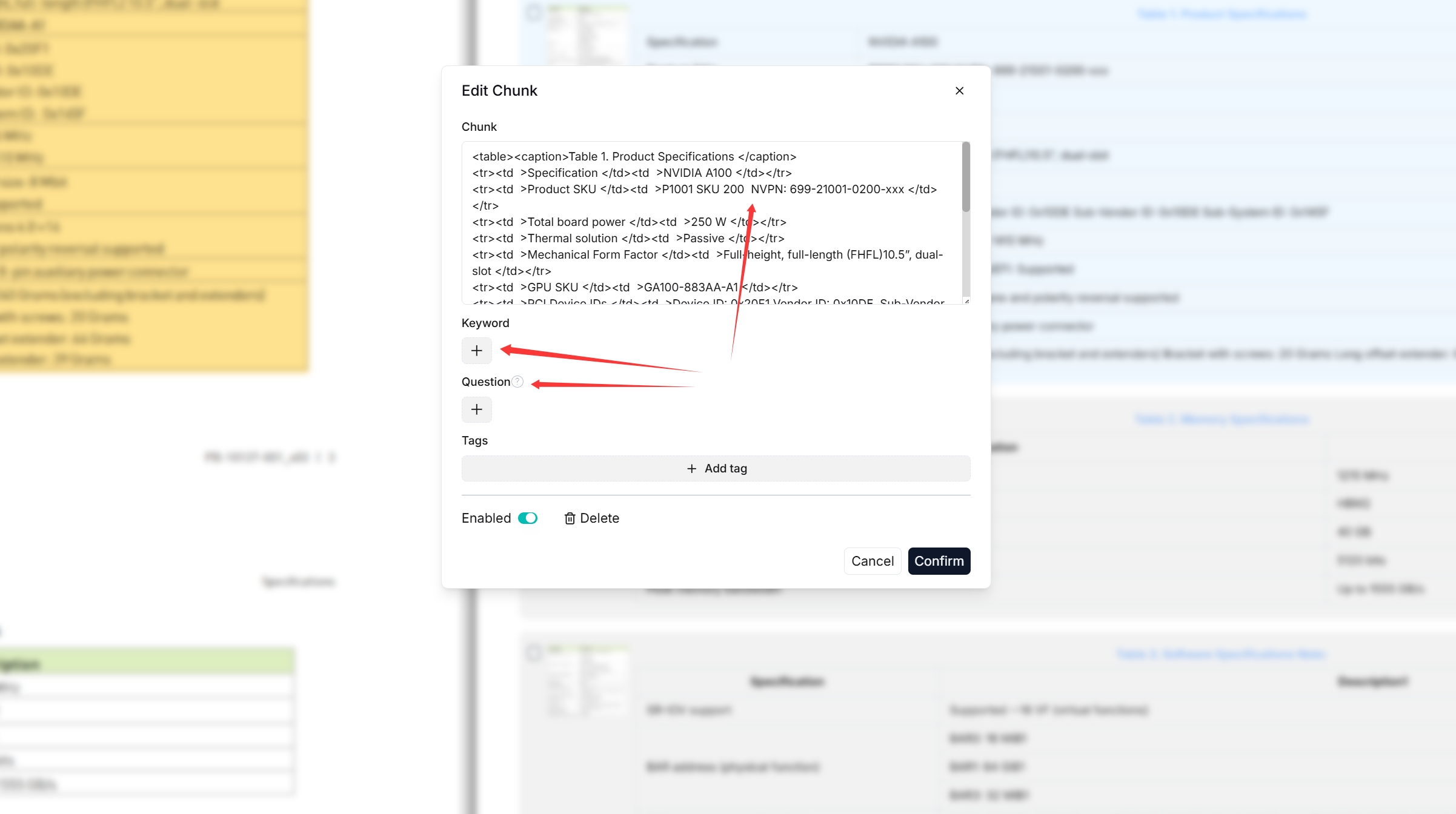
您可以为文件分块添加关键词或问题,以提高其在包含这些关键词的查询中的排名。此操作会增加其关键词权重,并可以提高其在搜索列表中的位置。
-
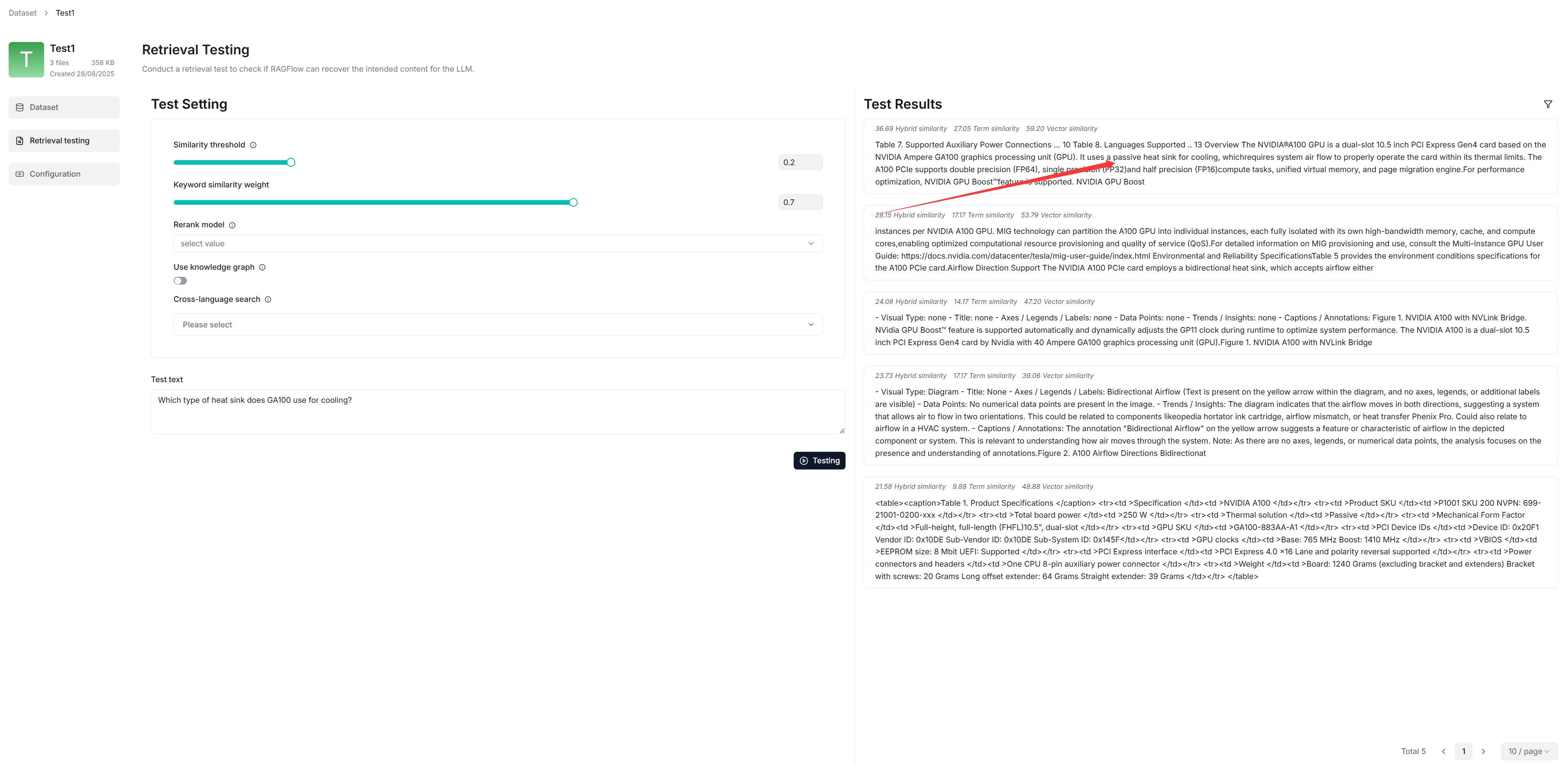
在检索测试中,在测试文本中提出一个快速问题以再次检查您的配置是否有效:
从以下内��容可以看出,RAGFlow 用真实的引用进行响应。
设置 AI 聊天
RAGFlow 中的对话基于特定的知识库或多个知识库。一旦您创建了知识库并完成了文件解析,您就可以开始 AI 对话了。
-
点击页面顶部中间的聊天标签 > 创建聊天以显示聊天配置对话框用于您的下一个对话。
RAGFlow 为每个对话提供选择不同聊天模型的灵活性,同时允许您在系统模型设置中设置默认模型。
-
更新助手设置:
- 为您的助手命名并指定您的知识库。
- 空响应:
- 如果您希望将 RAGFlow 的答案限制在您的知识库范围内,请在此处留下响应。然后当它无法检索到答案时,它会统一响应您在此处设置的内容。
- 如果您希望 RAGFlow 在无法从您的知识库中检索到答案时即兴发挥,请将其留空,这可能会产生幻觉。
-
更新提示引擎或在开始时保持原样。
-
更新模型设置。
-
现在,让我们开始:
