智能体组件
配备推理、工具使用和多智能体协作能力的组件。
智能体组件微调 LLM 并设置其提示。从 v0.20.5 开始,智能体组件能够独立工作并具备以下能力:
- 基于环境反馈进行自主推理、反思和调整。
- 使用工具或子智能体完成任务。
使用场景
当您需要 LLM 协助总结、翻译或控制各种任务时,智能体组件是必不可少的。
前提条件
- 确保您已正确配置聊天模型:

- 如果您的智能体涉及知识库检索,请确保您已正确配置目标知识库。
快速开始
1. 点击智�能体组件以显示其配置面板
相应的配置面板出现在画布右侧。使用此面板定义和微调智能体组件的行为。
2. 选择您的模型
点击模型,从下拉菜单中选择聊天模型。
如果没有显示模型,请检查您是否在模型提供商页面添加了聊天模型。
3. 更新系统提示(可选)
系统提示通常定义您模型的角色。您可以保持系统提示不变,或自定义它以覆盖默认设置。
4. 更新用户提示
用户提示通常定义您模型的任务。您会发现 sys.query 变量已自动填充。输入 / 或点击 (x) 以查看或添加变量。
在此快速开始中,我们假设您的智能体组件是独立使用的(下方没有工具或子智能体),那么您可能还需要使用 formalized_content 变量指定检索到的块:
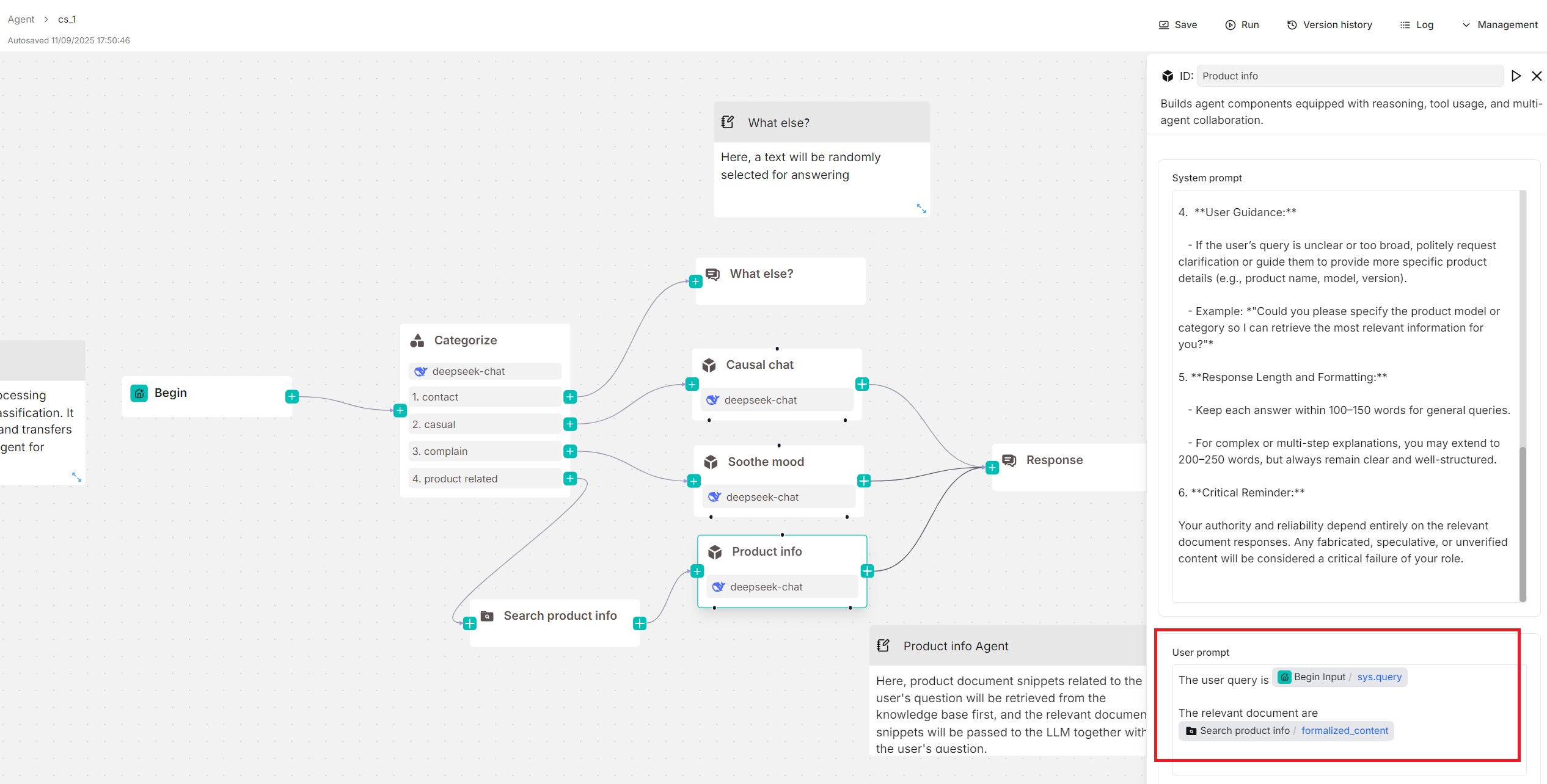
5. 跳过工具和智能体
+ 添加工具和**+ 添加智能体部分仅在您需要将智能体组件配置为规划器(下方有工具或子智能体)时使用。在此快速开始中,我们假设您的智能体**组件是独立使用的(下方没有工具或子智能体)。
6. 选择下一个组件
必要时,点击智能体组件上的**+**按钮,从下拉列表中选择工作流中的下一个组件。
作为客户端连接到 MCP 服务器
在本节中,我们假设您的智能体将配置为规划器,下方有一个 Tavily 工具。
1. 导航到 MCP 配置页面

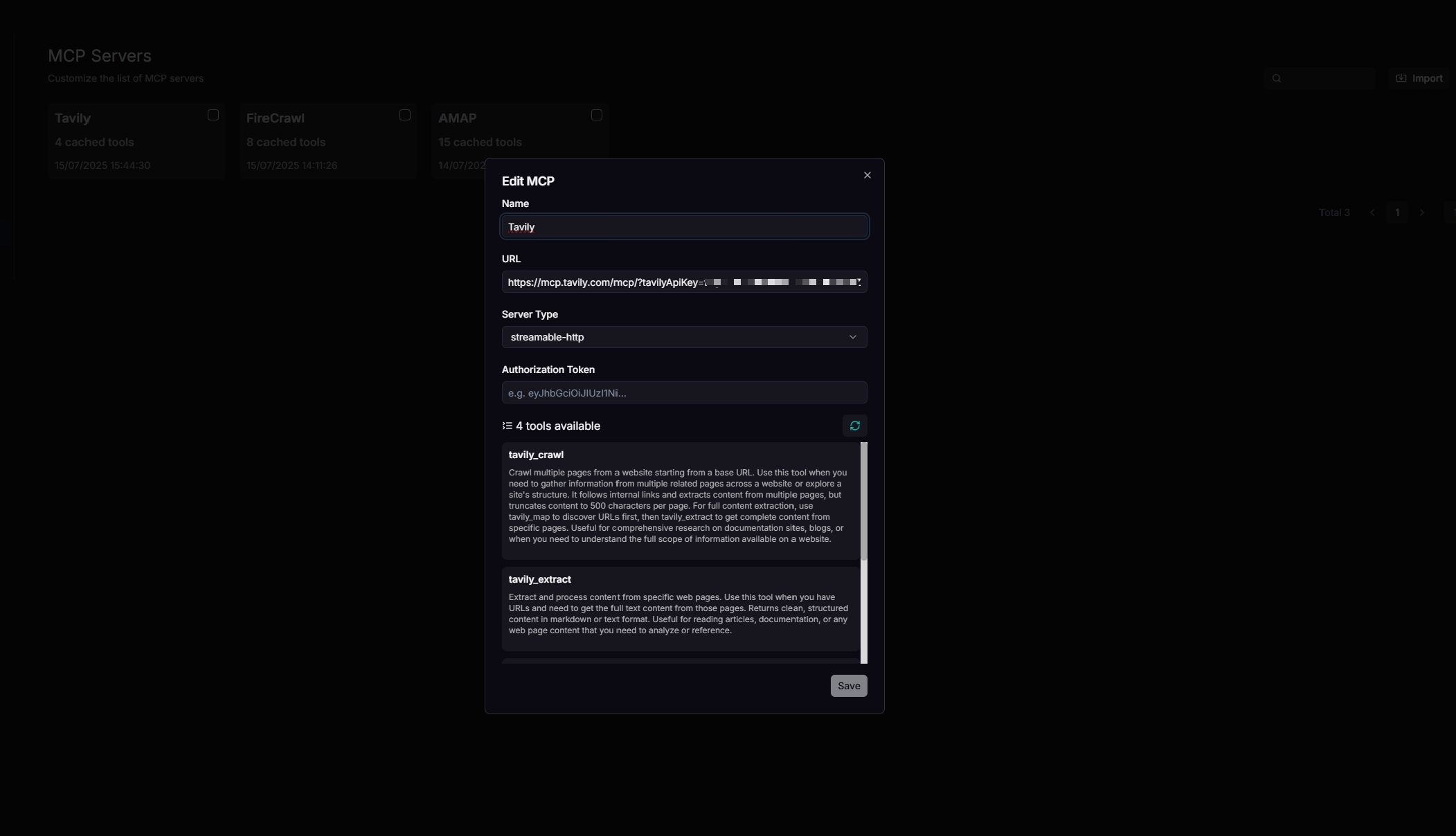
2. 配置您的 Tavily MCP 服务器
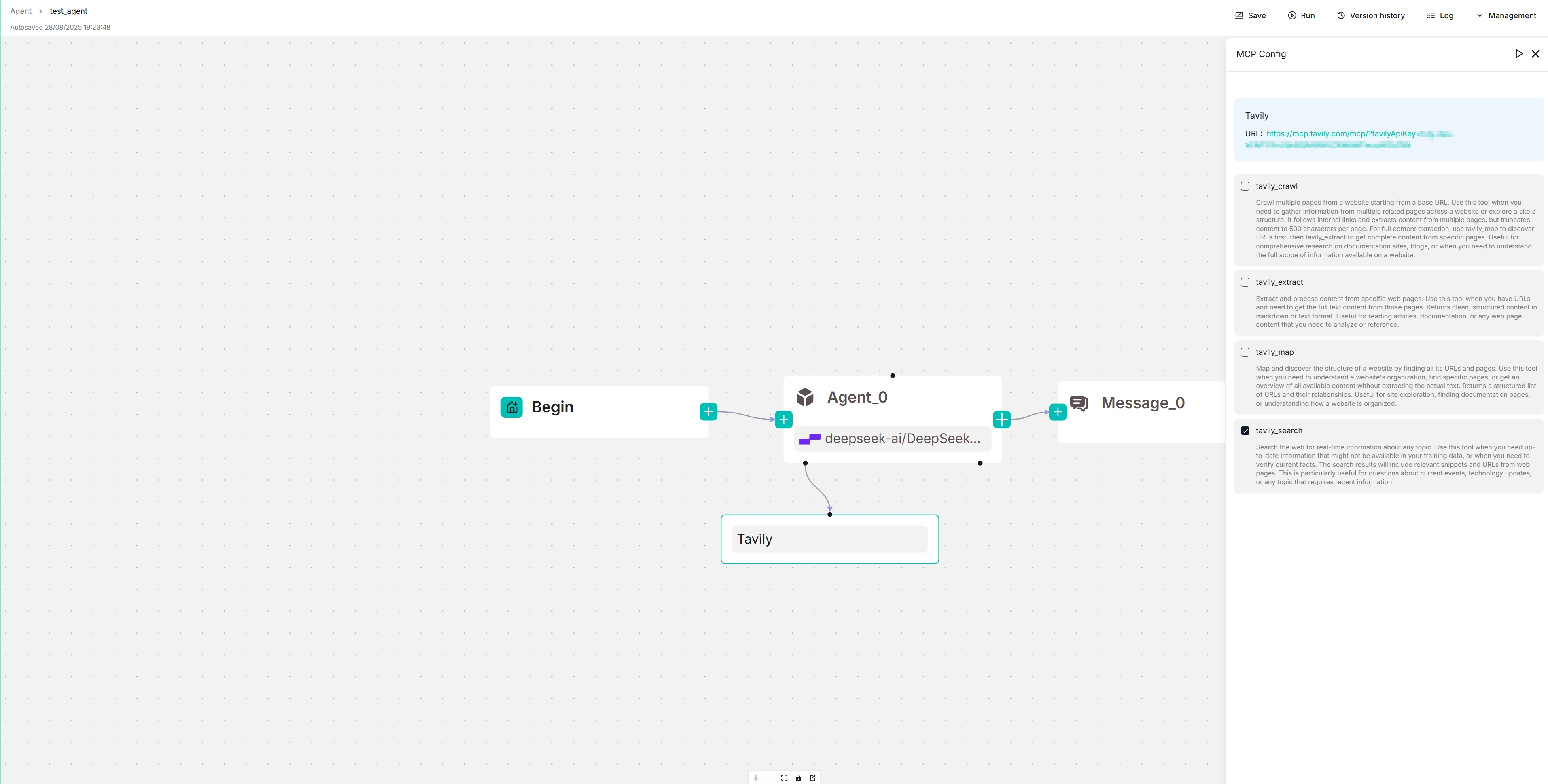
更新您的 MCP 服务器名称、URL(包括 API 密钥)、服务器类型和其他必要设置。配置正确后,将显示可用工具。
3. 导航到您的智能体编辑页面
4. 连接到您的 MCP 服务器
- 点击**+ 添加工具**:
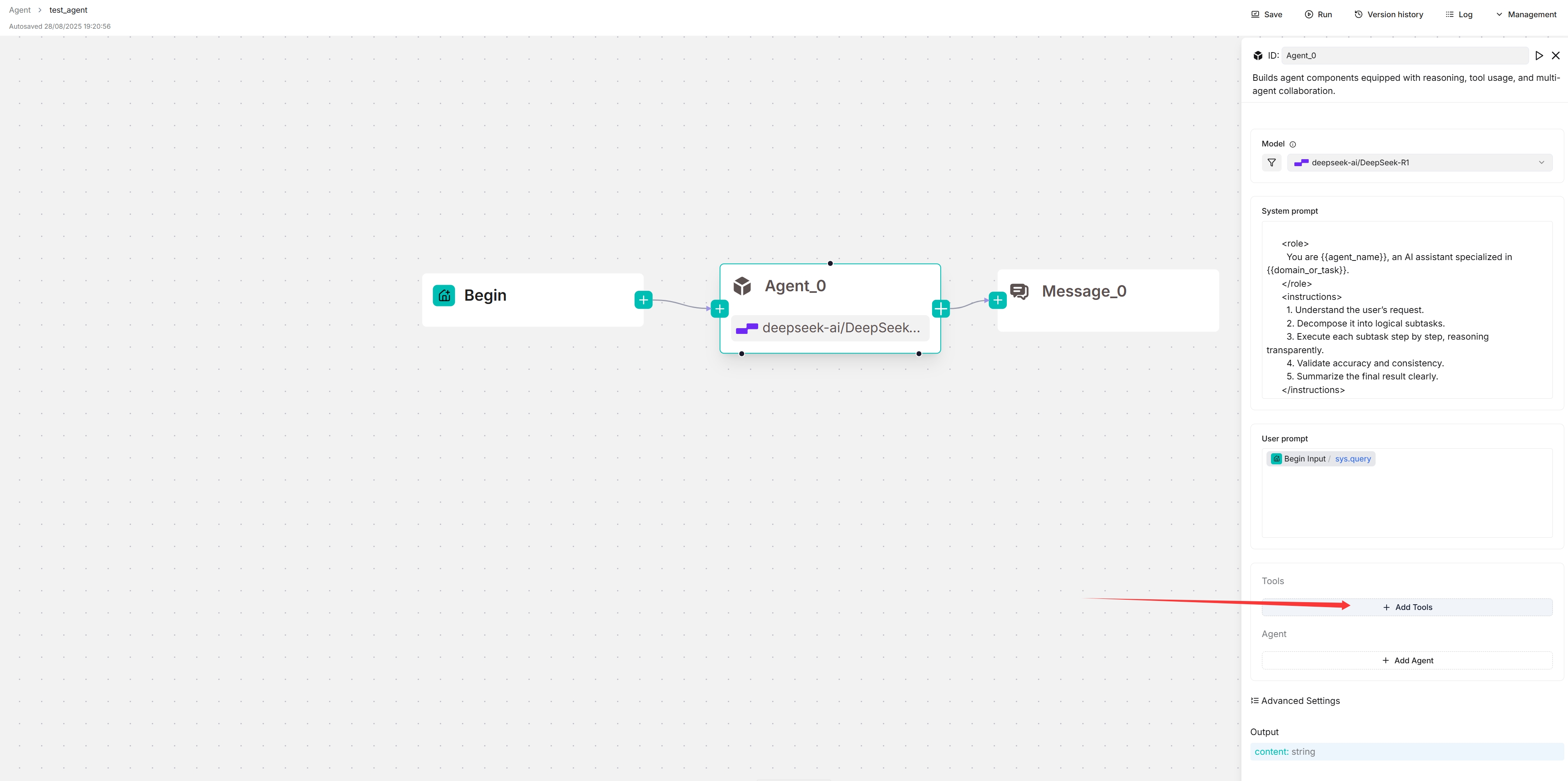
-
点击MCP以显示可用的 MCP 服务器。
-
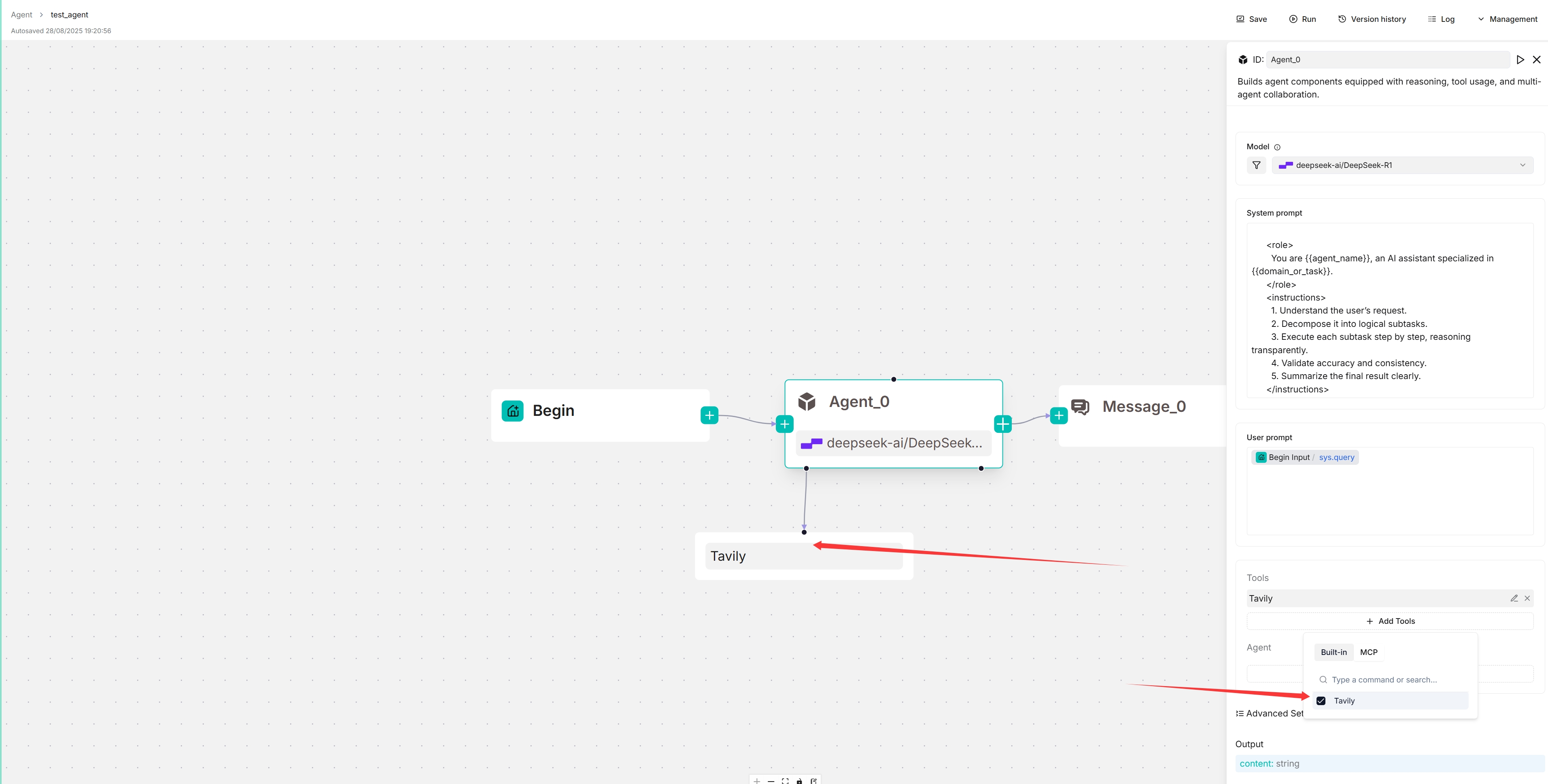
选择您的 MCP 服务器:
目标 MCP 服务器出现在您的智能体组件下方,您的智能体将自主决定何时调用它提供的可用工具。
5. 更新系统提示以指定触发条件(可选)
为确保可靠的工具调用,您可以在系统提示中指定哪些任务应该触发每个工具调用。
6. 查看您的 MCP 服务器的可��用工具
在画布上,点击新填充的 Tavily 服务器以查看和选择其可用工具:
配置
模型
点击模型的下拉菜单以显示模型配置窗口。
- 模型:要使用的聊天模型。
- 确保您在模型提供商页面上正确设置了聊天模型。
- 您可以为不同组件使用不同模型以提高灵活性或改善整体性能。
- 自由度:温度、Top P、存在惩罚和频率惩罚设置的快捷方式,表示模型的自由度级别。从即兴、精确到平衡,每个预设配置对应温度、Top P、存在惩罚和频率惩罚的唯一组合。
此参数有三个选项:- 即兴:产生更具创意的响应。
- 精确:(默认)产生更保守的响应。
- 平衡:即兴和精确之间的中间地带。
- 温度:模型输出的随机性级别。
默认为 0.1。- 较低的值导致更确定性和可预测的输出。
- 较高的值导致更具创意和多样化的输出。
- 温度为零时,相同提示会产生相同输出。
- Top P:核采样。
- 通过设置阈值 P 并将采样限制为累积概率超过 P 的令牌,减少生成重复或不自然文本的可能性。
- 默认为 0.3。
- 存在惩罚:鼓励模型在响应中包含更多样化的令牌范围。
- 较高的存在惩罚值使模型更可能生成尚未包含在生成文本中的令牌。
- 默认为 0.4。
- 频率惩罚:阻止模型在生成的文本中过于频繁地重复相同的单词或短语。
- 较高的频率惩罚值使模型在使用重复令牌时更加保守。
- 默认为 0.7。
- 最大令牌:
- 不必为所有组件坚持使用同一模型。如果特定模型在特定任务上表现不佳,请考虑使用不同的模型。
- 如果您不确定温度、Top P、存在惩罚和频率惩罚背后的机制,只需选择预设配置的三个选项之一。
系统提示
通常,您使用系统提示来描述 LLM 的任务,指定它应该如何响应,并概述其他杂项要求。我们不打算详细阐述这个主题,因为它可能像提示工程一样广泛。但是,请注意系统提示通常与键(变量)结合使用,这些键作为 LLM 的各种数据输入。
智能体组件依靠键(变量)来指定其数据输入。其直接上游组件不一定是其数据输入,工作流中的箭头仅表示处理顺序。智能体组件中的键与系统提示结合使用,为 LLM 指定数据输入。使用正斜杠 / 或 (x) 按钮显示要使用的键。
高级用法
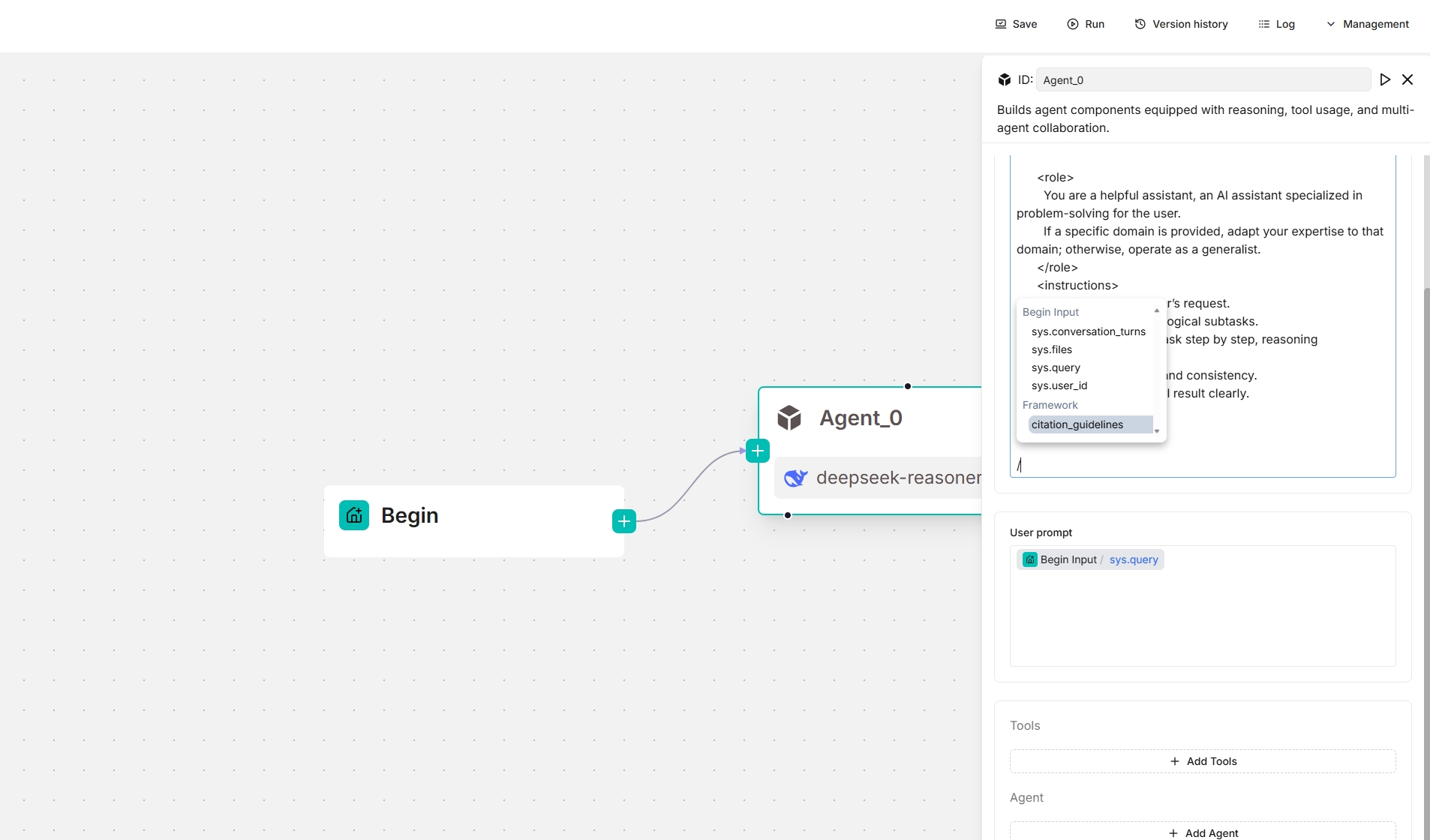
从 v0.20.5 开始,系统提示字段中提供四个框架级提示块,使您能够在框架级别自定义和覆盖提示。输入 / 或点击 (x) 查看它们;它们出现在下拉菜单的框架条目下。
task_analysis提示块- 此块负责分析任务——用户任务或当智能体组件充当子智能体时由主导智能体分配的任务。
- 参考设计:analyze_task_system.md 和 analyze_task_user.md
- 仅当此智能体组件充当规划器(下方有工具或子智能体)时可用。
- 输入变量:
agent_prompt:系统提示。task:主导智能体或子智能体的用户提示。主导智能体的用户提示由用户定义,而子智能体的用户提示由主导智能体在委派任务时定义。tool_desc:可调用的工具和子智能体的描述。context:操作上下文,存储智能体、工具和子智能体之间的交互;初始为空。
plan_generation提示块- 此块基于任务分析结果为智能体组件创建要执行的下一个计划。
- 参考设计:next_step.md
- 仅当此智能体组件充当规划器(下方有工具或子智能体)时可用。
- 输入变量:
task_analysis:当前任务的分析结果。desc:当前被调用的工具或子智能体的描述。today:今天的日期。
reflection提示块- 此块使智能体组件能够反思,提高任务准确性和效率。
- 参考设计:reflect.md
- 仅当此智能体组件充当规划器(下方有工具或子智能体)时可用。
- 输入变量:
goal:当前任务的目标。它是主导智能体或子智能体的用户提示。主导智能体的用户提示由用户定义,而�子智能体的用户提示由主导智能体定义。tool_calls:工具调用历史call.name:被调用工具的名称。call.result:工具调用的结果
citation_guidelines提示块- 参考设计:citation_prompt.md
下面的屏幕截图显示了智能体组件可用的框架提示块,既作为独立组件,也作为规划器(下方有 Tavily 工具):
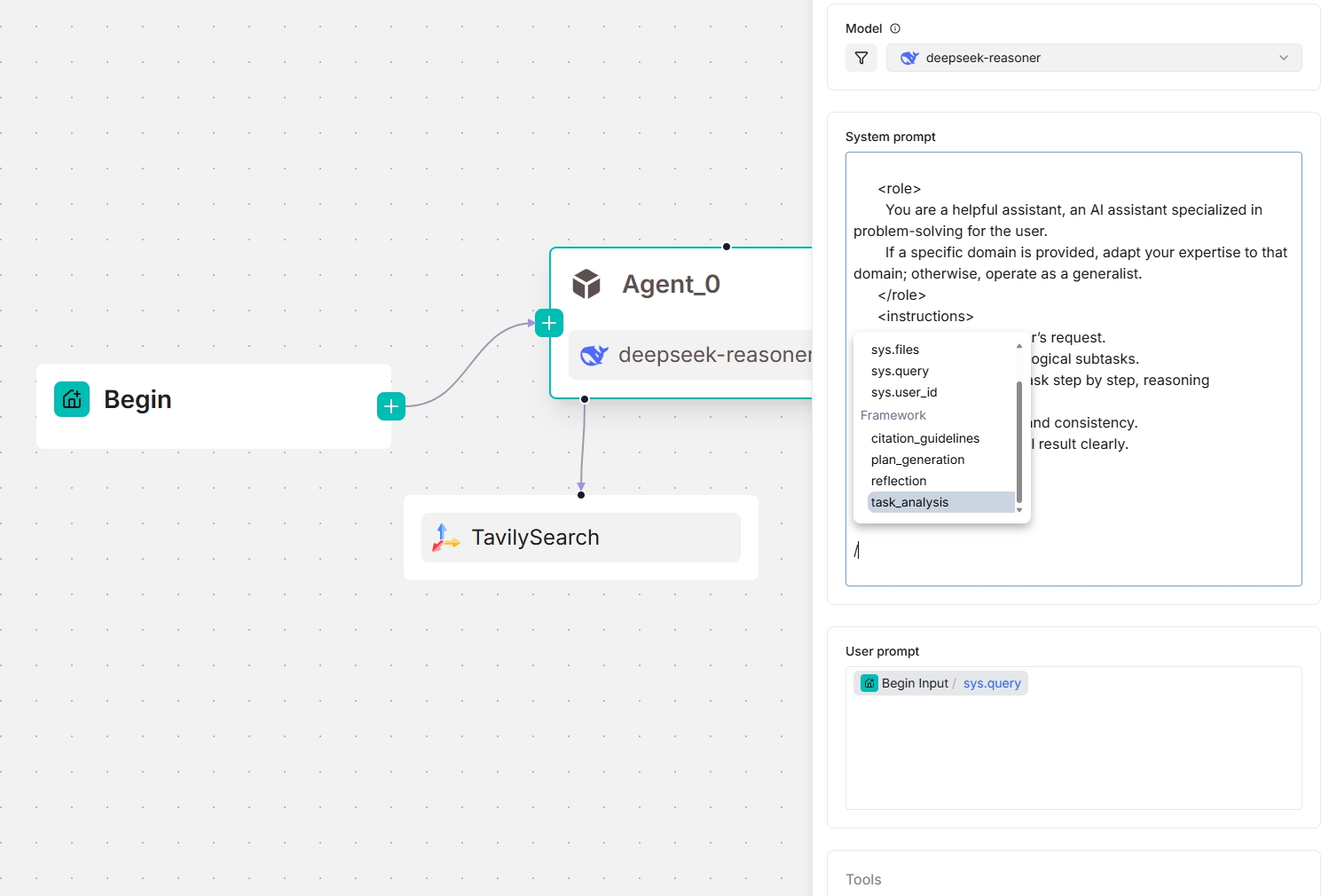
用户提示
用户定义的提示。默认为 sys.query,即用户查询。一般来说,当将智能体组件用作独立模块(不作为规划器)时,您通常需要在此处指定相应检索组件的输出变量(formalized_content)作为 LLM 输入的一部分。
工具
您可以将智能体组件用作协作器,在其他工具的帮助下进行推理和反思;例如,检索可以作为智能体的此类工具之一。
智能体
您将智能体组件用作协作器,在子智能体或其他工具的帮助下进行推理和反思,形成多智能体系统。
消息窗口大小
指定要输入到 LLM 的先前对话轮数的整数。例如,如果设置为 12,则最后 12 轮对话的令牌将馈送给 LLM。此功能消耗额外的令牌。
此功能仅用于多轮对话。
最大重试次数
定义智能体在停止或报告失败之前重试失败任务或操作的最大尝试次数。
错误后延迟
智能体在重试失败任务之前观察的等待时间(以秒为单位),有助于防止立即重复尝试并允许系统条件改善。默认为 1 秒。
最大反思轮数
定义所选聊天模型的最大反思轮数。默认为 1 轮。
增加此值将显著延长您智能体的响应时间。
输出
智能体组件输出的全局变量名,可由工作流中的其他组件引用。
常见问题
为什么我的智能体响应时间这么长?
智能体的响应时间通常取决于两个关键因素:LLM 的能力和提示,后者反映任务复杂性。使用智能体时,您应该始终平衡任务需求与 LLM 的能力。有关详细信息,请参阅如何平衡任务复杂性与智能体的性能和速度?。
最佳实践
如何平衡任务复杂性与智能体的性能和速度?
-
对于简单任务,如检索、重写、格式化或结构化数据提取,使用简洁的提示,移除规划或推理指令,强制执行输出长度限制,并选择较小的或 Turbo 类模型。这显著减少延迟和成本,对质量影响最小。
-
对于复杂任务,如多步推理、跨文档合成或基于工具的工作流,保持或增强包含规划、反思和验证步骤的提示。
-
在多智能体编排系统中,将简单子任务委托给使用较小、更快模型的子智能体,并保留更强大的模型供主导智能体处理复杂性和不确定性。
专注于最小化输出令牌——通过总结、要点或明确的长度限制——因为这比优化输入大小对减少延迟有更大的影响。