选择 PDF 解析器
选择用于解析 PDF 的视觉模型。
RAGFlow 不是一刀切的解决方案。它专为灵活性而构建,支持更深度的自定义以适应更复杂的用例。从 v0.17.0 开始,RAGFlow 将 DeepDoc 特定的数据提取任务与PDF 文件的分块方法解耦。这种分离使您能够自主选择用于 OCR(光学字符识别)、TSR(表格结构识别)和 DLR(文档布局识别)任务的视觉模型,以平衡速度和性能来适应您的特定用例。如果您的 PDF 只包含纯文本,您可以选择朴素选项来跳过这些任务,以减少整体解析时间。
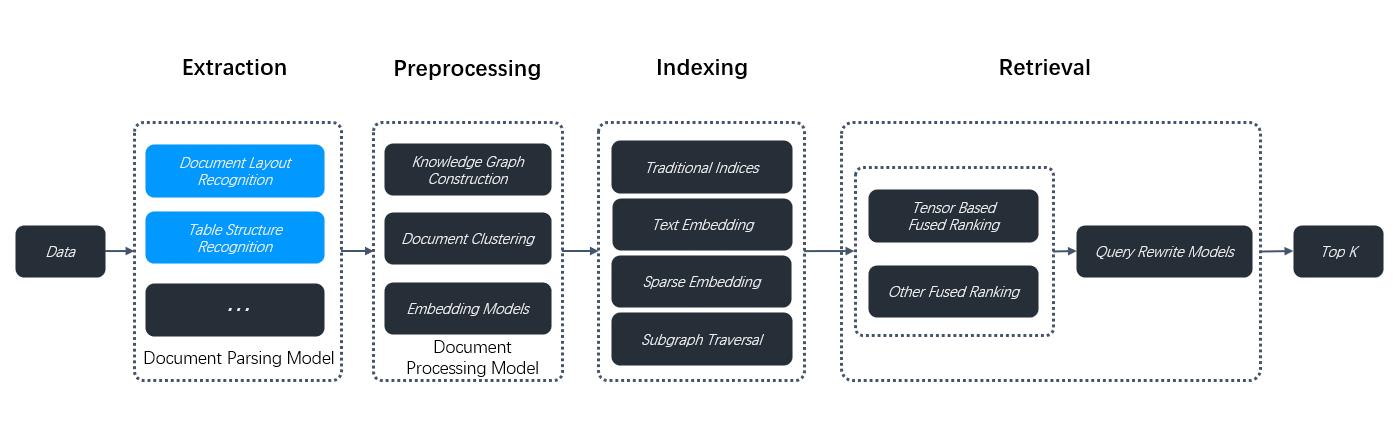
提取阶段(Extraction)
- 文档解析模型(Document Parsing Model) 包含:
- 文档结构识别(Document Structure Recognition):识别文档的整体结构和布局
- 表格结构识别(Table Structure Recognition):专门处理表格数据的结构化提取
- 其他处理模块(...):可能包括图像识别、OCR等功能
预处理阶段(Preprocessing)
- 文档处理模型(Document Processing Model) 包含:
- 知识图谱构建(Knowledge Graph Construction):将文档内容转换为结构化的知识图谱
- 文档聚类(Document Clustering):对文档进行智能分类和聚类(用蓝色高亮显示)
- 嵌入模型(Embedding Models):将文本转换为向量表示
索引阶段(Indexing) 建立多种索引机制:
- 传统索引(Traditional Indices) :基于关键词的传统搜索索引
- 文本嵌入(Text Embedding):密集向量索引
- 稀疏嵌入(Sparse Embedding):稀疏向量索引
- 子图遍历(Subgraph Traversal):基于知识图谱的索引结构
检索阶段(Retrieval)
- 融合排序系统:
- 基于张量的融合排序(Tensor Based Fused Ranking)
- 其他融合��排序(Other Fused Ranking)
- 查询重写模型(Query Rewrite Models):优化用户查询
- Top K :返回最相关的K个结果
前置要求
- PDF 解析器下拉菜单仅在您选择与 PDF 兼容的分块方法时出现,包括:
- 通用
- 手动
- 论文
- 书籍
- 法律
- 演示文稿
- 整体
- 要使用第三方视觉模型解析 PDF,请确保您已在模型提供商页面的设置默认模型下设置了默认的 img2txt 模型。
操作步骤
-
在知识库的配置页面上,选择分块方法,比如通用。
PDF 解析器下拉菜单出现。
-
选择最适合您场景的选项:
- DeepDoc:(默认)在 PDF 上执行 OCR、TSR 和 DLR 任务的默认视觉模型,可能比较耗时。
- 朴素:如果您的所有 PDF 都是纯文本,则跳过 OCR、TSR 和 DLR 任务。
- 特定模型提供商提供的第三方视觉模型。
警告
第三方视觉模型标记为实验性,因为我们尚未完全测试这些模型用于上述数据提取任务。
常见问题
我什么时候应该选择 DeepDoc 或第三方视觉模型作为 PDF 解析器?
如果您的 PDF 包含格式化或基于图像的文本而不是纯文本,请使用视觉模型提取数据。DeepDoc 是默认的视觉模型,但可能比较耗时。您也可以根据您的需求和硬件能力选择轻量级或高性能的 img2txt 模型。
我可以选择视觉模型来解析我的 DOCX 文件吗?
不可以。此下拉菜单仅适用于 PDF。要使用此功能,请先将您的 DOCX 文件转换为 PDF。